Imagine opening a new shop — and before the sign above the door has even been hung straight, the first burglars are already at the entrance, checking whether the lock holds.
Anyone who has ever administered a web server is familiar with this phenomenon: such servers are constantly exposed to requests from automated crawlers and bots — often within just seconds of being brought online for the first time.
In this blog post, we want to look into where these bots come from and what they are searching for. We will also show some of the ways bots discover new web services in the first place, and how you can most effectively protect your web server against automated attacks.
Test Setup
To observe the first minutes in the life of a web server for this article, we set up a brand-new server using Caddy. We used the following configuration (the “Caddyfile”):
This configuration tells Caddy to log every incoming request to a JSON file called “access.jsonl” and to respond to all clients with the text “Hello World!”.
Next, we created the DNS record “demo.nsd.li” pointing to the corresponding IP address and allowed traffic on TCP port 443 in the firewall. We then started the server with the command “caddy run”. Immediately after startup, Caddy requested an appropriate TLS certificate from the certificate authority “Let’s Encrypt”. After a few seconds, the “fresh” web server was finally online.
Timeline
The following sections are based on an analysis of “access.jsonl” after 24 hours. As expected, the first requests already arrived within the first 15 seconds after the server went live:
| Time since start | Event |
| 0 seconds | Web server started |
| 30 seconds | TLS certificate request completed; web server online |
| 33 seconds | First crawling requests for / and /favicon.ico |
| 45 seconds | First requests probing for vulnerabilities |
The following figure shows the number of incoming requests during the first five minutes:

The figure shows an initial “burst” after about a minute, which subsides after roughly three minutes. After that, the rate of requests drops off into a kind of “background noise”, as the following representation of the first 24 hours illustrates:

Even longer observation periods of several days showed this same “background noise”. Overall, even this small evaluation makes it clear that bots launch their first attacks — or “probes” for vulnerabilities — within seconds of a server going live. But where do they come from, and what are they looking for?
Where the Requests Come From
The question of attribution is, as so often in IT security, extremely difficult to answer. To get a rough overview, we first mapped the source IP addresses to their respective organisations and countries using a database:

This breakdown of the most frequent sources is dominated by cloud providers such as Amazon/AWS, DigitalOcean, Iway, and Google. However, one cannot assume that these companies are themselves commissioning the scans.
Rather, attackers are happy to make use of such infrastructure: it allows servers to be spun up quickly and cheaply — and shut down again just as easily, at the latest once the associated IP address ends up on a blocklist (as a result of the scans). On top of that, the same cloud providers are used by a wide range of legitimate services, which means that security teams cannot simply block all IP ranges belonging to them.
Analysing the First Requests
That brings us to the second question: what are the attackers looking for? To answer this, we manually analysed the first requests and tried to map them to specific vulnerabilities, or at least to certain types of interfaces. The following table shows our interpretation of the first roughly 25 requests:
| Path | Description |
| / | Root directory; normal crawling |
| /favicon.ico | Website icon; normal crawling |
| /@vite/env | Environment variables for vite |
| /.vscode/sftp.json | Configuration file for the Visual Studio Code plugin SFTP; potentially contains SFTP credentials |
| /.env | File with environment variables that may contain, for example, credentials or database connection strings |
| /.git/config | Configuration file indicating the presence of a Git repository |
| /console/ | Likely an administration interface |
| /server | Likely an administration interface |
| /server-status | Status page for the Apache mod_status module |
| /about | Likely a general information page |
| /login.action | Likely a login page |
| /v2/_catalog | Docker Registry V2 API |
| /.DS_Store | macOS metadata file; potentially contains sensitive data |
| /ecp/Current/exporttool/microsoft.exchange.ediscovery.exporttool.application | Probe for the Microsoft Exchange eDiscovery Export Tool (indicator for vulnerability CVE-2021-34473) |
| /graphql, /api, /api/graphql, /graphql/api, /api/gql | Search for GraphQL endpoints |
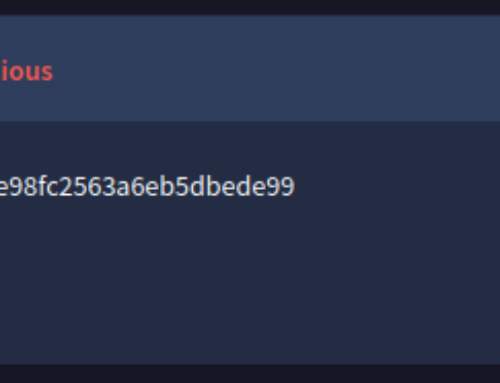
| /s/434313e243e25393e21383/_/;/META-INF/maven/com.atlassian.jira/jira-webapp-dist/pom.properties | Attempt to exploit vulnerability CVE-2021-26086 in Atlassian Jira |
| /config.json | Likely a general configuration file |
| /swagger-ui.html, /swagger/index.html, /swagger/swagger-ui.html | Search for REST API documentation generated with Swagger |
| /.well-known/security.txt | Contact information for security incidents |
| /telescope/requests | Search for Laravel Telescope |
Broadly speaking, these requests can be classified into the following categories:
- “Fingerprinting”, i.e. identifying the software in use
- Searching for interfaces (for example, for administration or debugging)
- Searching for configuration files, backups, or source code repositories
- Probing for known vulnerabilities
It is also striking how directly and purposefully the bots go after paths that are of interest to attackers — they need no links or other references to find them.
How Are the Targets Chosen?
To be precise, two distinct activities are relevant here: discovering the web servers themselves, and then selecting which paths to probe.
Let’s start with the web servers. A very reliable source of domain names for new web servers are Certificate Transparency Logs, which we covered in a previous blog post. These are public logs that record every TLS certificate issued by a public certificate authority (CA). Since virtually all websites are accessible over HTTPS today (and that’s a good thing!), their hostnames can be found in these logs. Entries in Certificate Transparency Logs can even be observed “live”, for example with certstream or a more recent implementation such as certstream-server-go. This data source allows attackers to discover new (HTTPS-protected) web servers within seconds, without ever sending a single request to the systems themselves. It is reasonable to assume that our demo web server was discovered in exactly this way.
There are many other ways to discover services — including those not protected by TLS — for example (and likewise passively) through DNS databases or hyperlinks, or actively through port scans or DNS brute-forcing, i.e. systematically trying out possible hostnames. Listing all of these techniques would go beyond the scope of this blog post.
Now to the paths. To begin with, there are wordlists containing URLs like the ones shown above. The best-known collection is probably the GitHub repository SecLists. Another project is “Assetnote Wordlists”, where lists of URLs (or relative paths) are generated automatically from public sources. Specialised tools — such as ffuf, gobuster, and feroxbuster — can then automatically issue a request for each entry and analyse the response. Attackers also exploit the fact that some web servers reveal the existence of directories through their redirect behaviour. The following listing illustrates the difference using this very website. First, a non-existent path is requested — the server responds with HTTP status code 404:
If, instead, an existing path is requested, the web server automatically redirects to a URL with a trailing slash (/) appended:
In this case, the response shows an attacker that the directory “/wp-admin” apparently exists — even if the attacker has no access to the directory itself.
Some of the tools mentioned earlier exploit this behaviour to systematically discover directories and then search within them for resources matching the relative paths from their wordlists.
Countermeasures
A brief interim summary: attackers — or rather their automated bots — start probing public web servers within seconds of them going online. They obtain hostnames of target systems, for example, from Certificate Transparency Logs. What they look for is known vulnerabilities (i.e. outdated software), accidentally exposed sensitive information, misconfigurations, and administration or debugging interfaces.
It is, of course, tempting to try to hide one’s own web server from attackers. For instance, using a wildcard certificate could buy a certain amount of time, since it would obscure the specific subdomain in use. In our experience, however, such measures fall under the heading of “security through obscurity”. Over the past few years, Certificate Transparency Logs have established themselves as a reliable source of information — but it is by no means certain that further sources won’t emerge in the years to come. And once a system has been uncovered and is listed in a public database, all the effort invested in “security through obscurity” is wasted.
The only truly effective countermeasure, therefore, is to securely configure web servers before connecting them to the internet. What exactly “secure” means depends on the specific application, but at the very least the following best practices should be followed:
- Minimise the attack surface — disable any functionality that isn’t needed.
- Provide extra protection for “internal” interfaces (used for administration or debugging), e.g. by restricting access to specific IP addresses in addition to requiring login credentials (defense in depth).
- Replace default passwords with strong passwords.
- Install updates — the system should not contain any known vulnerabilities.
- Follow the principle of least privilege — for example, by isolating the web server at the network level from other systems and from the internal network.
Hardening a system in line with these best practices alone can already mitigate a majority of automated attacks.